I would like to make a Content Management System for my daughter’s nursery. They keep the daily information about the children in notebooks full of very easy to lose post its and hope this app can help with it. The daily information will be referred to as activities.
The app provides a database and web interface for users to:
* Sign up, log in or log out securely as a nursery staff or parent.
* Nursery staff can create, read, update, and delete (CRUD) an activity.
* Parents can read only the personal profile page of their children.
* User inputs are validated.
Sinatra is a Domain Specific Language implemented in Ruby that’s used for writing web applications.
My first steps to create the app are:
-Create a repository in Github.
-The project structure following the MVC conventions.
-Set my environment and my config.ru. I am following the Modular Sinatra Pattern and having a config.ru file is one convention of it. The purpose of config.ru is to detail to Rack (Sinatra gem is built on top of Rack) the environment requirements of the application and start the application, mount my application controllers. Rack is a convention, or specification, that lets web applications “plug” into a common interface for handling HTTP requests. To actually serve requests, we need a web server — something that can translate HTTP requests into Ruby calls. My gem ‘thin’ is a web server that do this job.
-Create my Gemfile with all gems that I am going to run trough Bundle, which is set up in my environment file.
Here are the gems I want to use:
Sinatra: to create my web application.
activerecord: it is my Object Relation Mapper, links my Ruby models with rows in my database table. It is a gem to have access to the database mapping and associations.
sinatra-activerecord: it gives me access to some Rake tasks.
rake: short for “ruby make”, it is a package that lets me quickly create files and folders, and automate tasks such as database creation.
require_all: for a simplier way to load code.
sqlite3: sqlite is a library that implements a SQL database engine. sqlite is my database adapter gem.
thin: it is a web server.
shotgun: this is my development server.
pry: my debugger.
bcrypt: it is a hashing algorithm for passwords.
tux: it gives me an interactive console that pre-loads my database and
ActiveRecord Associations.
rake: great gem to create actions and tasks, for example a pry console to test the models and the database. It needs a Rakefile in the root directory of the app with the environment specified and requiring ‘sinatra/activerecord/rake’.
Model classes
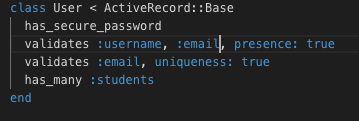
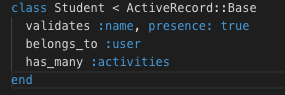
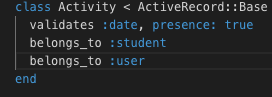
I think that I will need at least 3 models, User, Activity and Student.
1. User: stores user attributes, including:
* Username
* Email
* Password (Secured with Bcrypt hashing algorithm)
* Nursery_staff, a boolean value to indicate if a user is a nursery staff
2. Activity: stores activity attributes, including:
* Date
* User_id, to associate Activity to User
* Student_id, to associate Activity to Student
* Breakfast
* Morning Snacks
* Lunch
* Afternoon Snacks
* Sleep
* Nappies
* Comments
3. Student: stores student attributes, including:
* Name
* User_id, to associate Student to User
* Key person
* Room
Model Associations
User has many students and has many activities
Student has many activities and belongs to a User (parent).
Activity belongs to a Student and belongs to User.
Is it works?
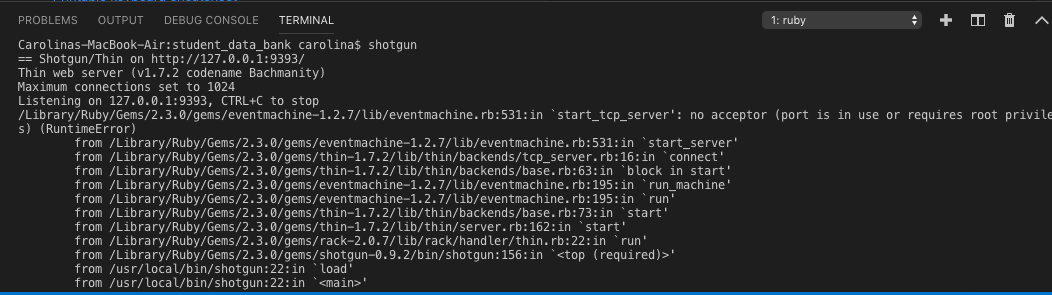
I am using Visual Studio Code and after creating the structure of my project with very basic info I tried to run shotgun and was getting the following error:
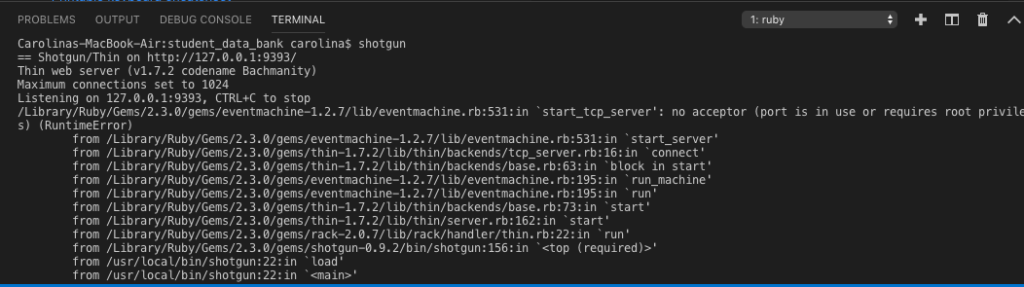
I had a server running in the background. After trying a lot of different things I could stopped it with the following I found in StackOverflow:

Ran lsof -i :9393 (9393 is the port I ran it on).
I killed the process using kill -9 *pid*. My pid was: 58152.
When I ran lsof -i :9393 again, nothing showed up.
I then ran shotgun and everything works fine now.
Model Validations
You can find all info about validations
here.
I will use in my controllers the methods save and update, which trigger validations for themselves and will save the object to the database only if the object is valid.
I will use some helpers to validate that some specified attributes are not empty. I want to make sure that a user gives an username and an email and that an activity has a date and a student has a name at least. I will validate the uniqueness of the email too.
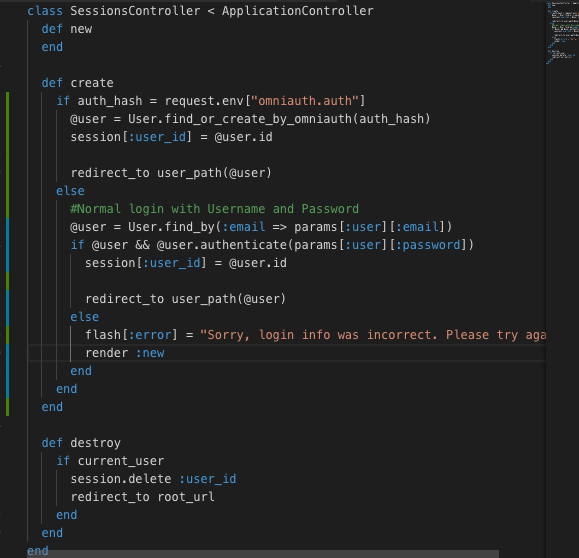
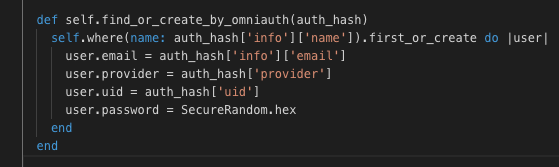
Authentication system
Enable sessions in your AppController and use the gem bcrypt. Make sure your user model has_secure_password and that on your users table you store the password like “password_digest“.
Protecting the session secret by Martin Fowler:
I changed my configuration to look like this:
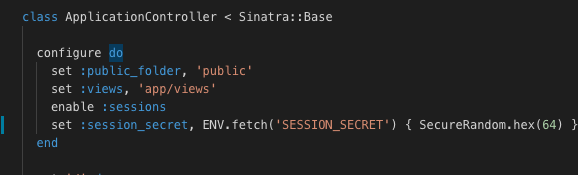
The password fails safe to a secure hex value if SESSION_SECRET is unset.
Database
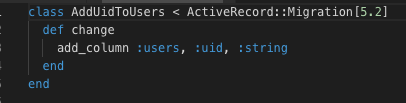
Create a Database folder (db), run your migrations to create your tables. I have created one table for the students, another table for my users and a last one for the activities.
I run:
rake db:create_migration NAME=create_students
rake db:create_migration NAME=create_users
rake db:create_migration NAME=create_activities
Then modify my migration tables according to my needs.
And finally run rake db:migrate, and all your tables will be added.
Play with my models and the database.
I run tux in my console but I got the following error
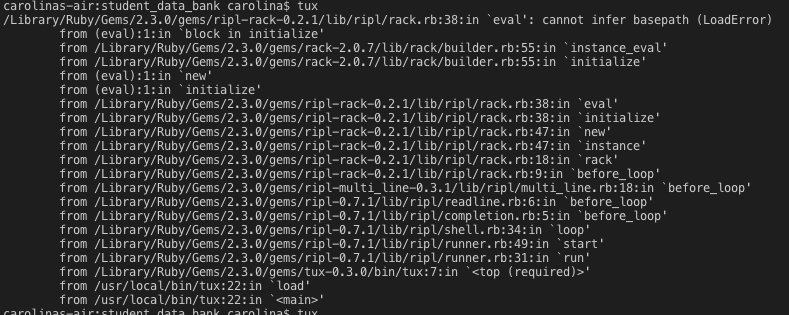
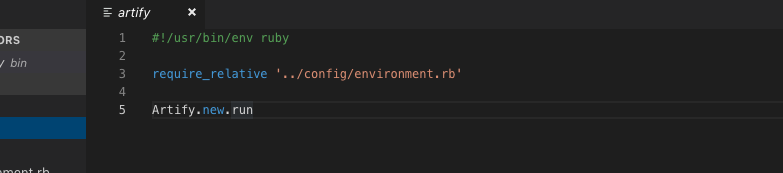
config.ru does not support require_relative so I changed my link and everything works fine!
Now it is time to be more creative and design my routes in the controllers and my views. I am using Bootstrap.
To check this project follow the link.