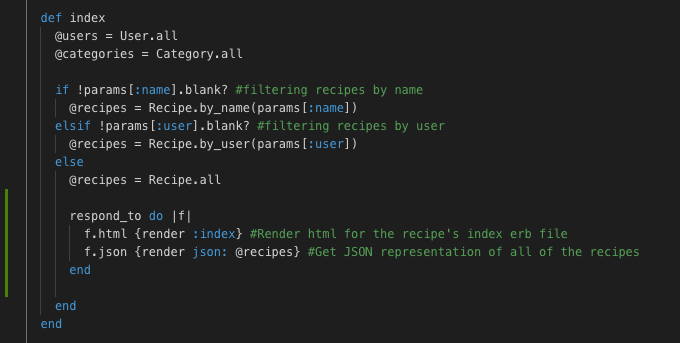
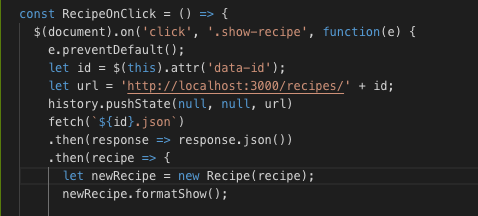
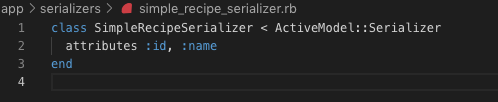
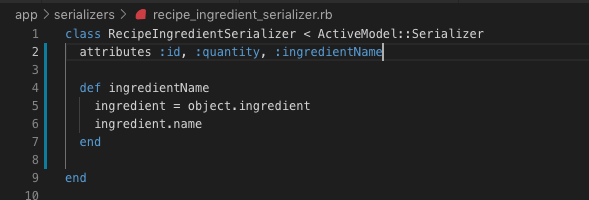
JavaScript engine makes multiply passes over the same code:
- First pass to parse the syntax. During this pass the engine undertakes a process called automatic semicolon insertion.
- Second pass to initialise variables and functions and store them in memory. Hoisting: is a JS default behaviour of moving all declarations to the top of the current scope ( to the top of the current script or the current function). Variables and constants declared with
let or const are not hoisted.
- The third pass is to actually execute the code line-by-line.
First and second passes are called the compilation phase and the third phase is called the execution phase.
Debugging:
No matter what combination of types you write, JS won’t throw an error and will return something, even a non sense and weird something.
- alert(“Hola!”);
- console.log(“Hola!”);
- console.error(“Hola!”);
- console.warn(“Hola!”);
- console.table
|
|
function Person(firstName, lastName) { this.firstName = firstName; this.lastName = lastName; } var me = new Person("Diana", "Badas"); console.table(me); |
try statement lets you test a block of code for errors.
catch statement lets you handle the error.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
function Myfunc() { this.twice=function(num){ if(num<2){ throw "num should be greater than 2" } return num*2; } } var myfunc = new Myfunc(); var list = new Array(0,4,1,3); for(var i=0; i<4; i++){ try{ var res = myfunc.twice(list[i]); console.log(res); } catch(e){ console.log(e); } } |
throw statement lets you create custom errors.
|
|
function getRectArea(width, height) { if (isNaN(width) || isNaN(height)) { throw "Parameter is not a number!"; } } try { getRectArea(3, 'A'); } catch(e) { console.error(e); // expected output: "Parameter is not a number!" } |
finally statement lets you execute code, after try and catch, regardless of the result.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
let letsTry = () => { try { // there is a SyntaxError eval('alert("Hello world)'); } catch(error) { console.error(error); // break the function completion return; } finally { console.log('finally') } // This line will never get executed console.log('after try catch') } letsTry(); |
Tests:
- Unit testing
- Integration testing
- End-to end testing
Operators:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
//Arithmetic operator **. The exponentiation operator returns the left number //raised to the power of the right number. 3 ** 3; => 27 //The remainder operator returns the remainder when the left number is divided //by the right number 5 % 2; => 1 //Order of the operations () ** * / % +- //Incrementing and Decrementing //JS has a pair of operators that we can use to increment and decrement a //numerical value stored in a variable ++ --. //If the ++ operator comes after the variable, the variable's value is returned first and then incremented. let count = 0; count++; => 0 count; => 1 Otherwise: let count = 5; --count; => 4 count; => 4 //Assignment operators let count = 0; count += 10; => 10 count -= 2; => 8 //Equality operators: == // Loose equality operator === /// Strict equality operator != // Loose inequality operator !== // Strict inequality operator //Relational operators > //Greater than >= //Greater than or equals < //Less than <= //Less than or equals //Logical operators //Use ! to negate an expression //Convert an expression to a boolean using !! //Link conditions with && and || //Return value of && is the falsy expression. The return value of the && //operator is always one of the two expressions. If the first expression is //falsy, && returns the value of the first expression. If the first expression //is truthy, && returns the value of the second expression. //Return value of || is the truthy expression. // The return value of the || operator is always one of the two expressions. //If the first expression is truthy, || returns the value of the first //expression. If the first expression is falsy, || returns the value of the //second expression. |
Data types:
Everything in JavaScript is data except:
- operators:
+, -, <=, etc.
- reserved words:
function, for, debugger, etc.
A basic type checking with the typeof operator: typeof(42);
The JS’s seven data types:
1.Numbers (primitive data type).
2. strings (primitive data type).
We use ‘single quotes’, “double quotes”, or `backticks.
String concatenation:
|
|
//Using the + operator: "This" + "is" + "a" + "string"; //Interpolation of variables and other JS expressions const number = 5; "This" + "is" + "my string number " + number + "." //Using template literals, using backticks. This is a string using a template literal, introduced with ES2015 I can interpolate my varirable ${number} here too! |
3. Booleans (primitive data type).
The following values are falsy:
false
null
undefined
0
NaN
'', ""
Every other value is truthy.
4.Symbols(primitive data type) are primarily used as an alternate way to add properties to objects.
5. Objects:
JS defines 5 types of primitive data types: string, number, boolean, null, undefined. All JS values, except primitives, are objects. In JS almost everything is an object: booleans, numbers and strings, if defined with the new keyword can be objects. Primitive data types represent single values, such as a number, a string or false, instead of a collection of values.
var x = new Boolean(false);
//typeof x returns object
JS objects: dates, maths, regular expressions, arrays, functions and objects.
Objects are similar to a hash in Ruby or a dictionary in Python. Arrays in JS are objects too.
All keys in an object are strings.
|
|
const diana = { name: "Diana", surname: "Badas", city: "London", favouriteColour: "blue" }; |
Access a value stored in an Object:
|
|
//.notation diana.name; //bracket notation diana["name"]; |
Add a property to an Object:
|
|
//.notation diana.university = "USC"; //bracket notation diana["age"] = "enough"; |
Delete an property
|
|
//.notation delete diana.age; //bracket notation delete diana["university"]; |
Arrays:
|
|
let dogs = ["Byron", "Cubby", "Boo Radley", "Luca"]; |
Add an element:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
//Destructively dogs.push("Snoopy"); => ["Byron", "Cubby", "Boo Radley", "Luca", "Snoopy"] dogs.unshift("Lassie"); => ["Lassie", "Byron", "Cubby", "Boo Radley", "Luca", "Snoopy"] //Using arr[arr.length] = b let dogs = ["Byron", "Cubby", "Boo Radley", "Luca"]; const moreDogs = ["Toby", "Luna"]; dogs[dogs.length] = moreDogs; => (2) ["Toby", "Luna"] dogs; => (5) ["Byron", "Cubby", "Boo Radley", "Luca", Array(2)] //Non-destructively //Using ... operator const allDogs = ["Rex", ...dogs]; allDogs; => ["Rex", "Lassie", "Byron", "Cubby", "Boo Radley", "Luca", "Snoopy"] dogs; => ["Lassie", "Byron", "Cubby", "Boo Radley", "Luca", "Snoopy"] //Using.concat const moreDogs = ["Toby", "Luna"]; const allConcatDogs = dogs.concat(moreDogs); |
Delete an element:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
let dogs = ["Byron", "Cubby", "Boo Radley", "Luca"] //Destructively dogs.pop(); //deletes the last element => "Luca" dogs; => ["Byron", "Cubby", "Boo Radley"] dogs.shift(); //deletes the first element => "Byron" dogs; => ["Cubby", "Boo Radley"] Array.splice() //Add and delete elements var arrDeletedItems = array.splice(start[, deleteCount[, item1[, item2[, ...]]]]) const numbers = [1, 3, 4, 6]; numbers.splice(1, 0, 2); // at index 1, remove 0 elements, add number 2 => [] //elements deleted numbers; => [1, 2, 3, 4, 6] numbers.splice(4, 1, 5); => [6] //elements deleted numbers; => [1, 2, 3, 4, 5] //Non-destructively Array.slice arr.slice([begin[, end]]) //begin index is included and end index is not included in the new array. const colours = ["red", "blue", "yellow", "green"]; colours.slice(2); => ["yellow", "green"] colours; => ["red", "blue", "yellow", "green"] colours.slice(1, 3) => ["blue", "yellow"] colours; => ["red", "blue", "yellow", "green"] |
6. Null (primitive data type). Null is an absent object, but when called with typeof returns object.
7. Undefined (primitive data type). It is like a “not yet assigned a value”.
Spread operator (…)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const target = { a: 1, b: 2 }; const source = { b: 4, c: 5 }; const returnedTarget = Object.assign(target, source); returnedTarget return value => {a: 1, b: 4, c: 5} //Object.assign changes the original array, it is destructive. target return value => {a: 1, b: 4, c: 5} const mergedObj = { ...target, ...source }; mergedObj return value => {a: 1, b: 4, c: 5} //... operator is not destructive. target return value => {a: 1, b: 2} |
Variables:
Start with a lower case and don’t use spaces, use camelCase.
Mind reserved words or future reserved words.
We can package both of the initialisation steps, declaration and assignment in a single line of code:
|
|
const name = "Diana"; => undefined |
Differences between var, const and let.
*Variables declared without a const, let, or var keywords are always globally scoped. You can avoid this using strict mode.
var:
var is function scoped. The scope is limited to the function within which it is defined. If it is defined outside any function, the scope of the variable is global. They are not block-scoped.
Can be reassigned.
var comes with a ton of baggage in the form of scope issues, for example, with var no error is thrown if you declare a variable twice.
let:
let is block scoped. The scope is limited to the block defined by curly braces {}.
Can be reassigned.
const:
const is block scoped. The scope is limited to the block defined by curly braces {}.
Can not be reassigned to anew value, but can be mutated.
|
|
const colours = ["blue", "red"]; colours.push("yellow"); => 3 colours; => ["blue", "red", "yellow"] colours = ["blue", "red", "yellow", "green"]; => VM2182:1 Uncaught TypeError: Assignment to constant variable. |
Conditional statements:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
if (condition) { doThis; } else { doThat; } if (condition) { doThis; } else if (condition2) { doThat; } else { doOtherThing; } //Switch switch(expression) { case x: //code block break; case y: //code block break; default: //code block } //Ternary operator condition ? expresion1 : expresion2; //I the condition returns a truthy value, run the code in expression1. I the condition returns a falsy value, run the code in expression2. |
Functions:
A function is an object that contains a sequence of JavaScript statements. Declaration:
|
|
const sayMyName = () => { console.log("Diana"); } |
Function calling or execution:
Parameters. They are locally scoped variables that are usable, scoped, to inside the function. Here name is our parameter.
|
|
const sayAname = (name) => { console.log(name); } |
JS will assign the argument of “Diana” to the parameter name when this function is called.
Function declaration vs function expression
The difference lies in how the browser loads them into the execution context.
Function declarations load before any code is executed.
Function expressions load only when the interpreter reaches that line of code.
If you try to call a function expression before it is loaded you get an error.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
//Function declaration function myFunc () { return 5; } => undefined //Anonymous function expression const myFunc = function () { return 5; } => undefined myFunc; => f(){ return 5; } myFunc(); => 5 //Named function expression const myFunc = function myFunc () { return 5; } |
|
|
myFunc(); function myFunc () { return 5; } => 5 ///////////// myFunc(); const myFunc = function () { return 5; } => Uncaught ReferenceError: Cannot access 'myFunc' before initialization |
Arrow functions:
Arrow functions do not have their own this, it uses whatever this is defined within the scope it is in.
Looping and iteration:
Iteration is the number of times a loop can be executed, while loop is the code which generate or causes expressions to be iterated.
Looping is the process of executing a set of statements repeatedly until a condition is met. It’s great for when we want to do something a specific number of times (for loop) or unlimited times until the condition is met (while loop).
Iteration is the process of executing a set of statements once for each element in a collection.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
//for loop const colours = ["blue", "red", "yellow"]; for (let i = 0; i < colours.length; i++) { console.log(`Colour ${colours[i]}`); } //while loop function printColours (colours) { let i = 0; while (i < colours.length) { console.log(`Colour ${colours[i]}`); i++; } return colours; } printColours(colours); //for...of. Good for arrays. Allow us to use const const colours = ["blue", "red", "yellow"]; for (const element of colours) { console.log(element); } //for...in. Good for objects. It iterates over the properties of //an object in an arbitrary order. let result = ''; const myObject = { a: 1, b: 2, c: 3 } for (const property in myObject) { result += myObject[property]; }; => '123' |
Creating object with JS
|
|
//Constructor function<code> function Person(first, last, email) { this.first = first; this.last = last; this.email = email; this.name = function() {return this.first + " " + this.last;}; } Person.prototype.sayHello = function() { console.log(`Hi! My name is ${this.first}`); }; let Nao = new Person("Nao", "Gonzalez", n"nao@gmail.com"); |
|
|
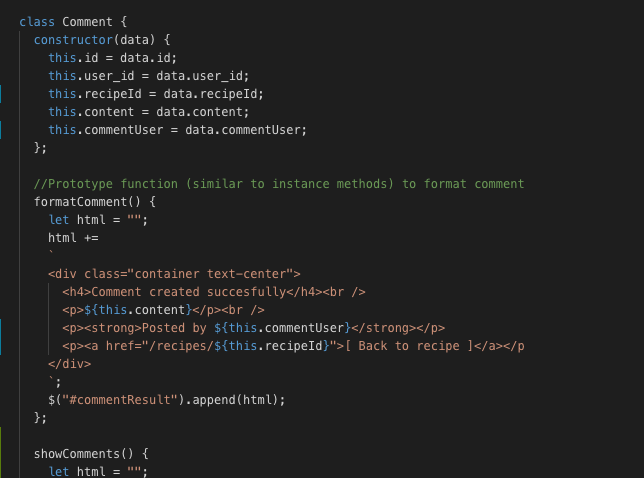
//Class syntax class Person { constructor(data) { this.first = first; this.last = last; this.email = email; this.name = function() {return this.first + " " + this.last;};</code> } } Person.prototype.sayHello = function() { console.log(`<code>Hi, my name is ${this.first}</code>`); } |
Definitions:
- S.O.L.I.D.: 5 principles of Object Oriented Design with JS.
- S: Single responsibility principle.
- O: Open closed principle. Open for extensions and closed for modifications, we shouldn’t introduce breaking changes to existing functionality.
- L: Liskov substitution principle. Every subclass should be substitutable for their parent class.
- I: Interface segregation principle. A client should never be forced to implement an interface that it doesn’t use or clients shouldn’t be forced to depend on methods they do not use.
- D: Dependency Inversion principle. Entities must depend on abstractions not on concretions. Importance of higher-order functions.
- ES6: “ES” ECMAScript, the official name of the JavaScript specification (Harmony – ES5)
- Higher Order function: Function that may receive a first-class function as an argument and can even return a function.
- First-class functions: Functions that are treated as objects or assignable to a variable.
- AJAX: Process of making requests for additional data became known as Asynchronous JavaScript and XML, or AJAX.
- Closure: When a function is able to remember and access its lexical scope even when that function is executing outside its lexical scope. A closure is a feature in JavaScript such that a function holds onto the variables that it had access to when it was declared. Closures can be used to declare functions that have specific variables always defined. JavaScript developers also take advantage of closures to encapsulate data, as we can declare our functions in such a way that the data is only accessible from the returned function, with no way to overwrite the variables captured by the closure.
|
|
function sayHi() { // 'scope of sayHi' is the lexical scope for printHi var myVar = 'hi!!'; return function printHi() { console.log(myVar); } } var myVar = null, greetings = sayHi(); greetings(); // 'hi!!' |
- Lexical scope: Where functions and variables are declared.
- Hoisting: It is JS’s default behaviour of moving declarations to the top of the current scope. Let and const are not hoisted. During a compilation, every declaration ( of variables or functions) are added to the relative scope. Function declaration hoisting differs from variables as the content of the function get hoisted too.
|
|
foo(); // ‘hola!’ function foo() { console.log(‘hola!’); } |
- Scope: Where something is available. In JS, where declared variables and methods are available within our code. Global scope, function scope, block scope, scope chain, lexical scope ( where functions and variables are declared).
|
|
function myFunction () { console.log(hello); var hello = "World!"; return hello; } myFunction(); => log: undefined => "World" |
- Recursion: A recursive function is a function that calls itself.
|
|
function countDown(n) { console.log(n); if(n >= 1) countDown(n-1); } countDown(5); |
- Call back: When we pass a function into another function where in it might be invoked, we refer to the passed function as a callback.
|
|
function doHomework(subject, callback) { alert(`Starting my ${subject} homework.`); callback(); } function alertFinished(){ alert('Finished my homework'); } doHomework('math', alertFinished); |
- forEach: Differences between map and forEach:
- forEach(): It simply calls a provided function on each element in your array. This callback is allowed to mutate the calling array. It returns undefined.
forEach() affects and changes our original Array. forEach() may be preferable when you’re not trying to change the data in your array, but instead want to just do something with it — like saving it to a database or logging it out.
- map(): creates a new array with the results of calling a provided function on every element in the calling array. The difference is that
map() utilises return values and actually returns a new Array of the same size. map() returns an entirely new Array — thus leaving the original array unchanged. And map() might be preferable when changing or altering data. Not only is it faster but it returns a new Array.
|
|
let arr = [1, 2, 3, 4, 5]; arr.forEach((num, index) => { arr[index] = num * 2; }); arr; => [2,4,6,8,10] let doubled = arr.map(num => { return num * 2; }); doubled; => [2,4,6,8,10] arr; => [1, 2, 3, 4, 5] |
- Statement vs expression: A statement is a unit of code that accomplish something but does not produce a value. An expression is a unit of code that produces a value.
- statements: variable declarations, iteration, control flow, debugging.
- this: keyword that refers to the object it belongs to. Safer if using arrow functions, because arrow function uses whatever
this is defined within the scope it is in.
- This, inside a standalone function will refer to the global object.
- Outside any function, this refers t the global object, in web browsers this is window.
- Inside an object method, this refers to the object that received the method call.
- Inside an standalone function, even one inside a method, this will default to the global object.
- When using strict mode in a standalone function, as we do inside classes, this will be undefined.
- We can use .bind, .call and .apply to control the value of this.